
IronOCR is a leading C# OCR library renowned for its accuracy, ease of use, and speed. With a user-friendly API, it swiftly extracts text from images and PDFs, enabling developers to integrate OCR functionality seamlessly into their .NET projects. Powered by Tesseract 5 OCR technology, IronOCR supports over 127 languages, making it versatile for diverse language requirements across various applications.
Designed for compatibility across a wide range of .NET languages and platforms, including .NET 8, 7, 6, 5, Core, Standard, and Framework, IronOCR operates smoothly on Microsoft Windows, macOS, Linux, Docker, Azure, and AWS environments. Its comprehensive support extends to various document types, including receipts, checks, invoices, and specialized documents, ensuring flexibility for different use cases.
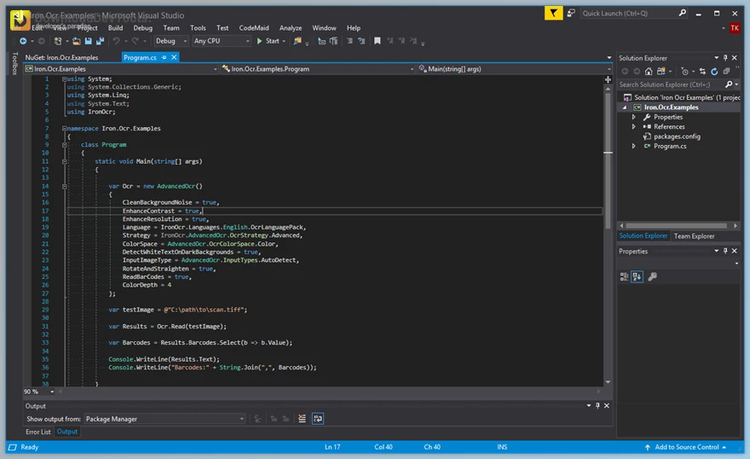
offers advanced features such as concurrency support for efficient processing, extensive input format support for images and PDFs, and sophisticated filters and image correction capabilities for enhancing OCR accuracy. Output options include simple text strings, structured data, and export to formats like searchable PDFs and HTML, facilitating seamless integration and utilization of OCR results in applications and comprehensive status tracking and analytics for monitoring OCR progress effectively.
Text extraction from images and PDFs
Support for over 127 languages with Tesseract 5 OCR technology
Compatibility with various .NET languages and platforms
Concurrency support for efficient processing
Reading text and barcodes from specialized documents
Comprehensive input format support, including images, PDFs, and more
Advanced filters and image correction capabilities
Output options such as simple text strings, structured data, and export to searchable PDFs and HTML
Comprehensive status tracking and analytics for monitoring OCR progress
